In This Topic
The fields collection is automatically populated with the data source columns and the extended [RowIndex] and [RowCount] fields. Each field has a Value and Name value descriptors (properties). The Value is the default field object value. The Value returns the respective data source column values for the current pivot scope (i.e. recordset).
Using Fields in Expressions
The data source column values in the context of the current scope recordset are referenced like this:
=Fields!FieldName
or
=Fields!FieldName.Value
where FieldName is the name of a data source column.
For example: if your data source has a column called MyField, you can reference it in any expression like this:
=Fields!MyField
or
=Fields!MyField.Value
In case the scope recordset contains a single record, the field value reference returns the record column value. In case the scope recordset contains multiple records, the field value reference returns an array of the column values - you typically enclose such references in an aggregate function (like SUM, MIN, MAX, FIRST, LAST etc.).
For the purpose of using data source column names in expressions, the original column names of the data source are normalized. The column name normalization basically converts a string containing any types of characters to a string that contains only letters, digits and the '_' character. The '_' is also used to replace all characters that are not letters, digits or '_'. This process alone can produce duplicates - for example PO# and PO% will both be normalized as PO_. Such conflicts are additionally resolved by adding an occurrence index, so PO# and PO% will be finally normalized as PO_ and PO_2. The Name property of a data source field however returns the original name of the data source column.
Extended Fields
The pivot engine automatically creates two extended fields - [RowIndex] and [RowCount]. You can think of the extended fields as system fields that is always present in any data source. Following are more details about them:
[RowIndex] - the row index is an automatically assigned zero-based index on each row from the data set. Like normal fields the row index field returns either a single variant or array of variant values depending on the number of records in the scope recordset. You can reference the row index like this:
=Fields![RowIndex]
or
=Fields![RowIndex].Value
[RowCount] - the row count is used to reference the number of records in the scope recordset - it always returns a single variant containing the row count. You can reference the row count like this:
=Fields![RowCount]
or
=Fields![RowCount].Value
There is no naming conflict even if your data set has a RowIndex or RowCount field, since they should be referenced without brackets. For example: =Fields!RowIndex rather than =Fields![RowIndex], which is reserved for the extended row index field.
Fields and Scopes
When an expression is evaluated it always has a current scope assigned. Because each scope is associated with a recordset, when you reference a field variable it by default returns the column values from the current scope recordset. You can change the scope in which a certain variable is referenced with the help of an optional prefix, which is placed before the variable reference.
Scopes are hierarchical in nature and are automatically managed by the pivot processor. Following is an overview of the scopes that you can use:
- Global - the global scope is always available and has the FULL recordset assigned.
- Pivot - the pivot scope is the only child of the Global scope. It references a FULL recordset filtered by the pivot filters. The Pivot scope can be used in all expressions, except the expressions of pivot filters.
- Parent - references the parent scope of the current scope. Parent scopes can be chained (e.g. Parent.Parent).
- Row - references the scope of the leaf row data member for a data cell. Only available in data cell expressions.
- Col - references the scope of the leaf col data member for a data cell. Only available in data cell expressions.
Lets see some examples, considering the sample data set described in Grouping, Filtering and Sorting:
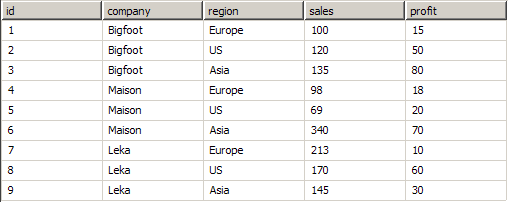
Let the pivot has a pivot filter:Type:Expression, Expression:=company="Bigfoot" and a pivot property P:="Showing " + Fields![RowCount] + " of " + Global.Fields![RowCount] + " records". The P value at runtime is - "Showing 3 of 9 records".
Let A be a root data grouping with group by expression:=Fields!company and let B be a child data grouping of A with group by expression:=Fields!region (e.g. group by company and then by region). If you want to show the percentage of sales of each region towards the company total sales, B must have a property P with expression:=SUM(Fields!sales)/SUM(Parent.Fields!sales)*100.
Let the pivot has a column data grouping with group by expression:=Fields!company and a row data grouping with a group by expression:=Fields!region (e.g. show companies in the columns and regions in the rows). The sales of for the company/region intersection in the data cell is computed as:=SUM(Fields!sales). Computing the percentage of total region sales is done with:=SUM(Fields!sales)/SUM(Row.Fields!sales)*100. Computing the percentage of total company sales is done with:=SUM(Fields!sales)/SUM(Col.Fields!sales)*100.
Fields Availability
The Fields collection can be used in all expressions, except the expressions that are part of a data source connection.